超越GPT-4o,Claude 3.5一夜封王!10倍编码速度逆天,全网最全实测来了
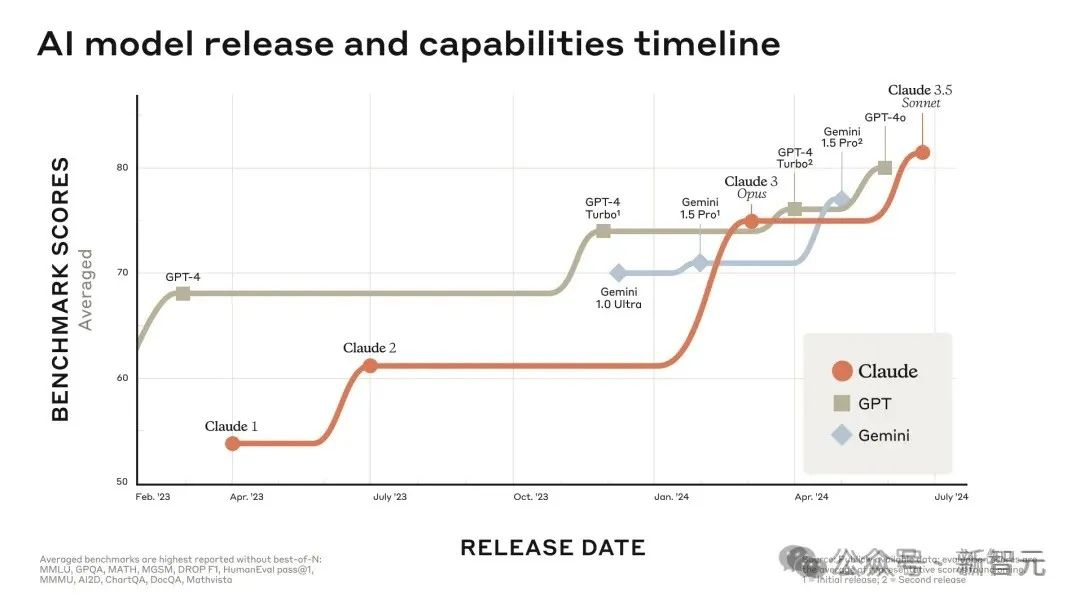
超越GPT-4o,Claude 3.5一夜封王!10倍编码速度逆天,全网最全实测来了昨夜上线的Claude 3.5 Sonnet,性能直接吊打了GPT-4o,甚至价格还更便宜。网友们纷纷展开实测,有人表示自己一半的工作已经可以由它替代了!而最让人惊喜的新功能,莫过于Artifacts了。
来自主题: AI资讯
10370 点击 2024-06-21 20:56
 搜索
搜索
昨夜上线的Claude 3.5 Sonnet,性能直接吊打了GPT-4o,甚至价格还更便宜。网友们纷纷展开实测,有人表示自己一半的工作已经可以由它替代了!而最让人惊喜的新功能,莫过于Artifacts了。
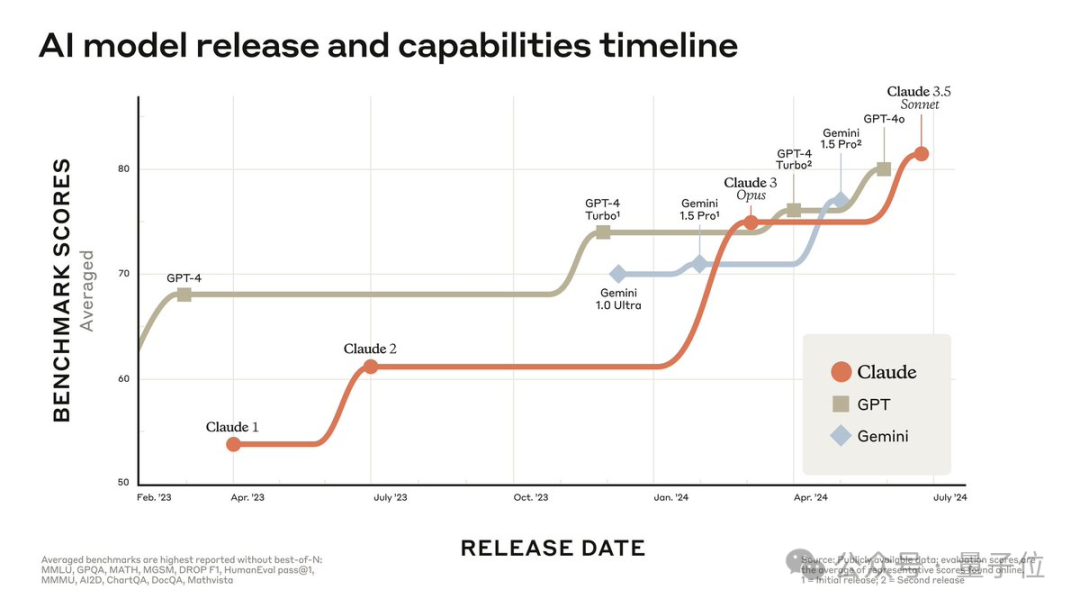
新鲜出炉的Claude 3.5 Sonnet,更快、更便宜,还是全球最强。

Claude大模型又双叒叕更新升级了!

今天, OpenAI劲敌Anthropic忽然丢炸弹,发布下一代旗舰大模型Claude 3.5 Sonnet。

Anthropic的25岁参谋长自曝因为深感AGI,未来三年自己的工作将被AI取代。她在最近的一篇文章中预言了未来即将要被淘汰的工种。难道说,Claude 3模型已经初现AGI了吗?

在云计算领域竞争最激烈的时代,亚马逊云科技曾提出,云计算的普惠是技术升级带来的。这个说法换到如今的生成式 AI 时代也是成立的。

一直以来,UC伯克利团队的LMSYS大模型排行榜,深受AI圈欢迎。如今,最有实力的全新大模型排行榜SEAL诞生,得到AI大佬的转发。它最大的特点是在私有数据上,由专家严格评估,并随时间不断更新数据集和模型。
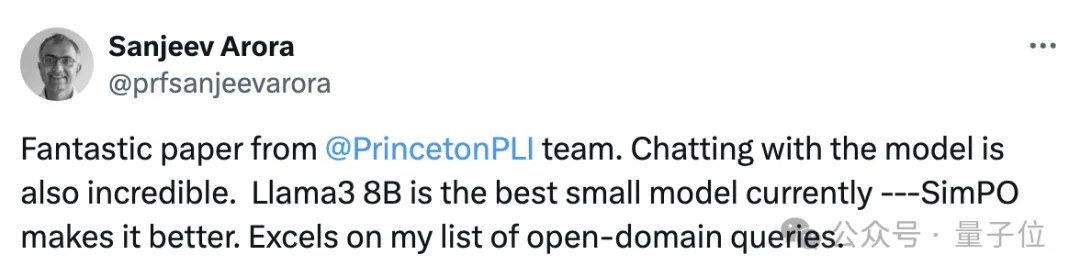
比斯坦福DPO(直接偏好优化)更简单的RLHF平替来了,来自陈丹琦团队。 该方式在多项测试中性能都远超DPO,还能让8B模型战胜Claude 3的超大杯Opus。 而且与DPO相比,训练时间和GPU消耗也都大幅减少。
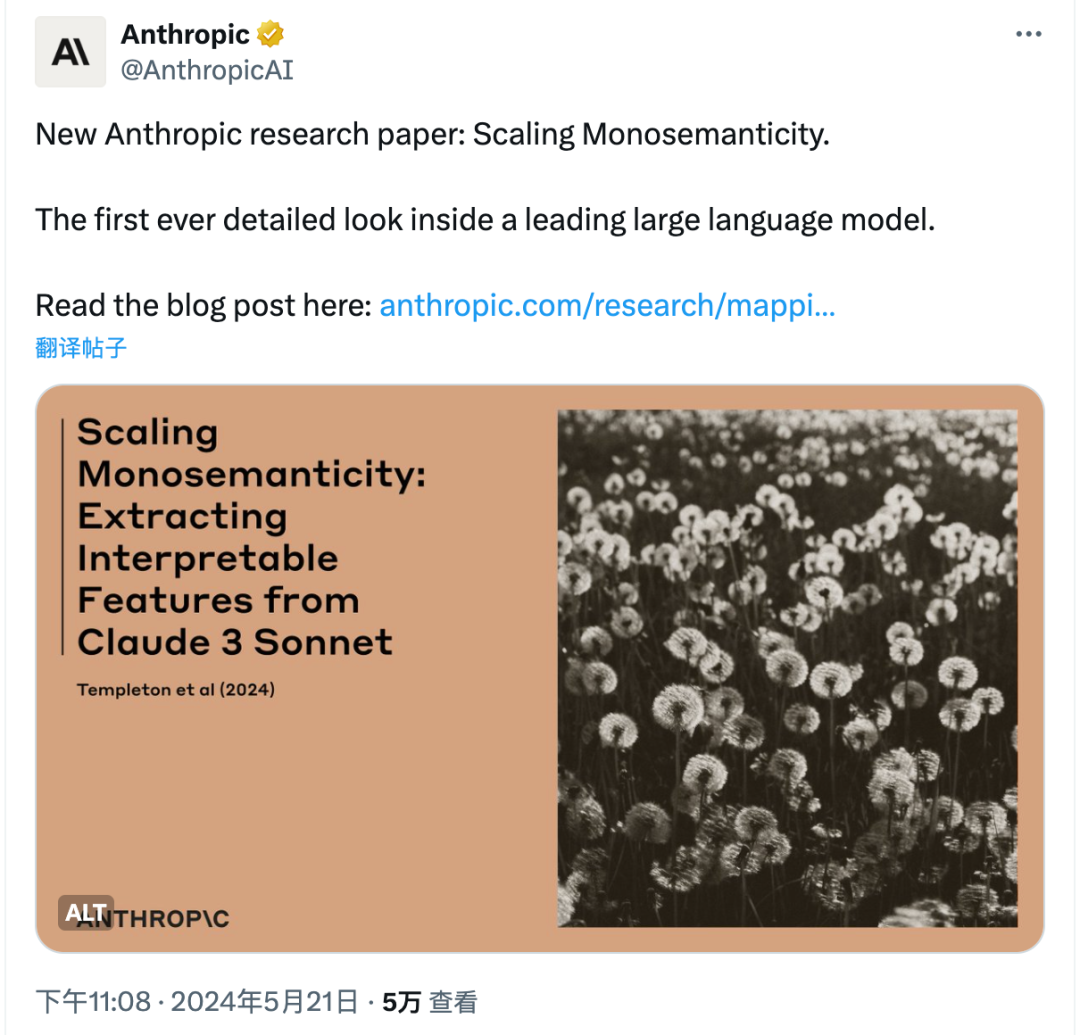
刚刚,Anthropic 宣布在理解人工智能模型内部运作机制方面取得重大进展。

I/O大会上,谷歌Gemini 1.5 Pro一系列更新让开发者们再次沸腾。最新技术报告中,最引人注目的一点是,数学专业版1.5 Pro性能碾压GPT-4 Turbo、Claude 3 Opus,成为全球最强的数学模型。